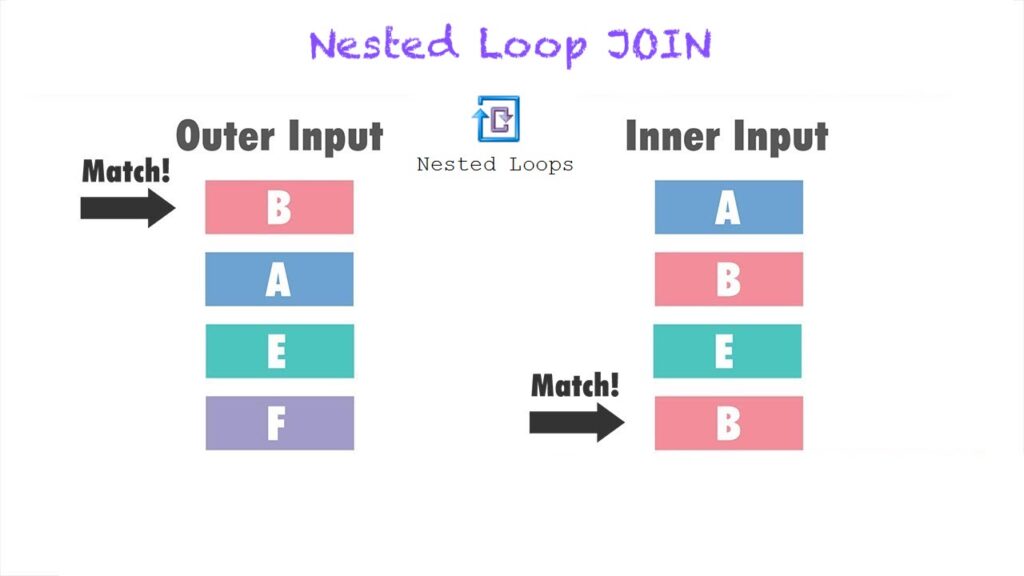
DB2 Nested Loop JOIN is used when one table is small and the other table is large. The smaller table is used to drive the join, and the larger table is used to look up the matching rows. This type of join can be beneficial in certain situations because of the following reasons:
Advantages of Nested Loop JOIN
- Low memory usage: Because the smaller table is used to drive the join, the join process does not require as much memory as other types of joins, such as sort-merge or hash joins. This can be beneficial when working with large data sets or when memory is limited.
- Fast for small tables: When the small table is used to drive the join, the join process can be very fast. The small table is scanned only once; for each row, the larger table is scanned to find the matching rows. This can be a good option for small data sets with high selectivity.
- Easy to implement: Nested loop join is a simple join algorithm that is easy to implement. It can be a good option when you want to quickly implement a join without having to worry about performance tuning.
- Good for small result set: Nested loop join is good when the result set is small because the join is performed row by row.
- Can be good for a certain type of filtering: Nested loop join can be efficient when the filtering conditions are on the outer table. This is because each row of the outer table is filtered and then scanned against the inner table.
Disadvantages of Nested Loop JOIN
- Performance: Nested loop joins can be slow when joining large tables, especially when the join condition is not selective enough. For every row in the first table, the nested loop join scans the entire second table, which can take a significant amount of time if the tables are large.
- Memory usage: Nested loop joins can also consume a lot of memory when joining large tables, as the entire second table must be loaded into memory for each iteration of the loop.
- Scalability: Nested loop joins can become a bottleneck when working with a large amount of data, as the join process becomes increasingly slow and memory-intensive as the data size increases.
- Inefficient with large data: Nested loop joins are inefficient when the data is large, as it will scan the entire table for each row in the first table, which can take a long time.
- Not suitable for distributed systems: Nested loop joins are not suitable for distributed systems, as they require a lot of communication between nodes and can become a bottleneck in distributed systems.
- Not suitable for parallel processing: Nested loop joins are not suitable for parallel processing, as they require a lot of communication between nodes and can become a bottleneck in parallel processing.
Use of Nested Loop JOIN
SELECT <columns> FROM <table1> JOIN <table2> ON <table1>.<column> = <table2>.<column>
Here are a few examples of how a nested loop join might be used:
- Joining a large table with a small table: If one table is much larger than the other, it may be more efficient to use a nested loop join to scan the smaller table for each row in the larger table, rather than scanning the larger table multiple times.
- Joining tables with a small number of matching rows: If the join condition only matches a small number of rows, a nested loop join may be more efficient than other join methods that require sorting or hashing the entire table.
- Joining tables with a unique key: If one of the tables has a unique key, a nested loop join can be used to quickly find the matching rows in the other table by looking up the key values in an index.
SELECT * FROM orders JOIN customers ON orders.customer_id = customers.id
In this example, the orders table is joined with the customers table on the customer_id column. The nested loop join method will match each row in the orders table with the corresponding row in the customers table.
Example of Nested Loop JOIN
Example-1
Tables:
- Employees:
- Columns: EmployeeID (Primary Key), EmployeeName, DepartmentID
- Departments:
- Columns: DepartmentID (Primary Key), DepartmentName
- Projects:
- Columns: ProjectID (Primary Key), ProjectName, EmployeeID
SELECT E.EmployeeName, D.DepartmentName, P.ProjectName FROM Employees E JOIN Departments D ON E.DepartmentID = D.DepartmentID JOIN Projects P ON E.EmployeeID = P.EmployeeID;
Explanation:
- Initial Join (Employees and Departments):
- The first join is between the Employees and Departments tables based on the common column DepartmentID. This join combines information about employees and their respective departments.
SELECT E.EmployeeName, D.DepartmentName FROM Employees E JOIN Departments D ON E.DepartmentID = D.DepartmentID;
Result: EmployeeName DepartmentName John HR Alice IT Bob Finance
Nested Join (Result with Projects):
- The result of the initial join is then used to perform a nested join with the Projects table based on the common column EmployeeID. This join combines information about employees, their departments, and the projects they are associated with.
SELECT E.EmployeeName, D.DepartmentName, P.ProjectName
FROM (SELECT E.EmployeeName, D.DepartmentName
FROM Employees E
JOIN Departments D ON E.DepartmentID = D.DepartmentID) AS Result
JOIN Projects P ON Result.EmployeeID = P.EmployeeID;
Result: EmployeeName DepartmentName ProjectName John HR ProjectA Alice IT ProjectB Bob Finance ProjectC
In this example, the nested join involves first combining information about employees and their departments, and then using that result to join with the Projects table to get a comprehensive result set with employee details, department information, and associated projects. The nested join allows for more complex relationships to be represented in the final result.
Example – 2
-- Sample data for the orders table orders +---------+------------+ | order_id | customer_id| +---------+------------+ | 1 | 1 | | 2 | 2 | | 3 | 3 | +---------+------------+ -- Sample data for the customers table customers +------------+-------------+-------------+ | customer_id| customer_name| region | +------------+-------------+-------------+ | 1 | John Doe | North | | 2 | Jane Smith | South | | 3 | Bob Johnson | East | +------------+-------------+-------------+ -- Sample data for the order_items table order_items +---------+------------+------------+ | order_id| product_id | quantity | +---------+------------+------------+ | 1 | 1 | 2 | | 2 | 2 | 3 | | 3 | 3 | 1 | +---------+------------+------------+ -- Sample data for the products table products +------------+----------------+-------+ | product_id | product_name | price | +------------+----------------+-------+ | 1 | iPhone | 800 | | 2 | MacBook Pro | 1500 | | 3 | Dell XPS | 900 | +------------+----------------+-------+
SELECT orders.order_id, products.product_name, customers.customer_name FROM orders JOIN customers ON orders.customer_id = customers.customer_id JOIN order_items ON orders.order_id = order_items.order_id JOIN products ON order_items.product_id = products.product_id WHERE customers.region = 'North' AND products.price > 1000
This query will return the following result:
+---------+----------------+----------------+ | order_id| product_name | customer_name | +---------+----------------+----------------+ | 1 | MacBook Pro | John Doe | +---------+----------------+----------------+
This example demonstrates how nested loop joins can be used to join multiple tables and filter the results based on specific conditions. In this example, we are joining the orders, customers, order_items, and products tables based on their respective ids and then filtering the results to show only the orders made by customers in the North region and products whose price is greater than 1000.
It’s important to note that this query can be slow if the tables are very large because, for every row in the orders table, it will scan the customers, order_items, and products tables. It’s also important to point out that the query’s performance can be improved by creating indexes on the columns used in the join and where clauses.
Performance improvement for nested loop joins in DB2
There are several ways to improve the performance of nested loop joins in DB2:
Indexing
Creating indexes on the join columns can significantly improve join performance by allowing DB2 to quickly locate the matching rows in the second table.
CREATE INDEX orders_order_id_idx ON orders (order_id); CREATE INDEX order_items_order_id_idx ON order_items (order_id); SELECT * FROM orders JOIN order_items ON orders.order_id = order_items.order_id WHERE orders.order_date > '2022-01-01'
In this example, indexes are created on the order_id column in both the orders and order_items tables. This allows DB2 to quickly locate the matching rows in the order_items table when performing the join, which improves performance.
Filtering
Using a subquery or a temporary table to filter the data in one of the tables before the join can greatly reduce the number of rows that need to be joined, which can improve performance.
CREATE TEMPORARY TABLE temp_suppliers AS ( SELECT supplier_id, supplier_name FROM suppliers WHERE country = 'USA' ); SELECT * FROM orders JOIN order_items ON orders.order_id = order_items.order_id JOIN products ON order_items.product_id = products.product_id JOIN temp_suppliers ON products.supplier_id = temp_suppliers.supplier_id WHERE orders.order_date > '2022-01-01'
In this example, a temporary table is created to filter the suppliers table to only include suppliers from the USA. This reduces the number of rows that need to be joined with the products table, which improves performance.
Limiting the number of rows returned
Using the “FOR FETCH ONLY” clause can be used to limit the number of rows that are returned from a join, which can help to improve performance and reduce memory usage when working with large result sets.
SELECT * FROM orders JOIN order_items FOR FETCH ONLY ON orders.order_id = order_items.order_id WHERE orders.order_date > '2022-01-01'
In this example, the “FOR FETCH ONLY” clause is used to limit the number of rows returned from the order_items table. This can help to improve performance and reduce the memory usage when working with large result sets.
Join Predicate Push-Down
“JOIN PREDICATE PUSH DOWN” allows DB2 to push the join conditions down to the data source, which can reduce the amount of data that needs to be transferred over the network and improve performance when joining tables that are stored in different databases or data sources.
SELECT * FROM orders JOIN remote_table ON orders.order_id = remote_table.order_id OPTIMIZE FOR 1 ROW WHERE orders.order_date > '2022-01-01'
In this example, the “OPTIMIZE FOR 1 ROW” clause is used to push down the join conditions to the remote data source, which can improve performance when joining tables that are stored in different databases or data sources.
Parallelism
Enabling parallelism during join operations allows DB2 to use multiple threads to perform the join operation, which can significantly speed up the query and improve performance when working with large tables.
SET CURRENT QUERY OPTIMIZATION = 'PARALLEL_JOIN'; SELECT * FROM orders JOIN order_items ON orders.order_id = order_items.order_id WHERE orders.order_date > '2022-01-01'
In this example, the parallelism is enabled by setting CURRENT QUERY OPTIMIZATION = ‘PARALLEL_JOIN’. This allows DB2 to use multiple threads to perform the join operation, which can significantly speed up the query and improve performance when working with large tables.
It’s worth noting that these are just examples, and the best join strategy will depend on the specific query and the data distribution.
Reducing the size of tables
Archiving or purging old data from large tables can reduce the number of rows that need to be joined, which can greatly improve performance.
Using Partitioned Tables
Partitioning large tables can improve performance by allowing DB2 to only join the partitions that contain the relevant data.
Tuning the join order: The order in which tables are joined can affect the performance of the query.
Choosing the Right Join Type
Choosing the correct type of join (inner, outer, cross) can help to improve performance.
Monitoring and analyzing the performance of the joins
Using tools like the DB2 Explain facility and the DB2 Performance Monitor can help to identify performance bottlenecks and fine-tune the query for optimal performance.