 POINTER is one of the data types in COBOL. A variable defined as data type POINTER can store the memory address of the other variables used in the program. There are different ways in which we can use POINTER variables in our program to achieve different tasks. One such example is retrieving data from “Linked list” or “Chained list”, the way data is being stored in IDMS. These variables are used for passing/sharing memory address across modules through COMMAREA in CICS.
POINTER is one of the data types in COBOL. A variable defined as data type POINTER can store the memory address of the other variables used in the program. There are different ways in which we can use POINTER variables in our program to achieve different tasks. One such example is retrieving data from “Linked list” or “Chained list”, the way data is being stored in IDMS. These variables are used for passing/sharing memory address across modules through COMMAREA in CICS.
You can define pointers in two ways:
- A pointer to a data item is defined with the USAGE POINTER clause. The resulting data item is called a pointer data item.
- A pointer to an ILE COBOL program, an ILE procedure, or a program object. This pointer is defined with the USAGE PROCEDURE-POINTER clause. The resulting data item is called a procedure-pointer data item.
A pointer data item can be used only in:
- A SET statement (Formats 5 and 7 only)
- A relation condition
- The USING phrase of a CALL statement, or the Procedure Division header
- The operand for the LENGTH OF and ADDRESS OF special registers.
A procedure-pointer data item can be used only in:
- A SET statement (Format 6 only)
- A relation condition
- The USING phrase of a CALL statement, or the Procedure Division header
- The operand for the LENGTH OF and ADDRESS OF special registers
- The CALL statement as a target.
For more information on Pointer please click here.
Explanation:
The reason why POINTER is used for sharing memory address across modules through COMMAREA in CICS is as follows
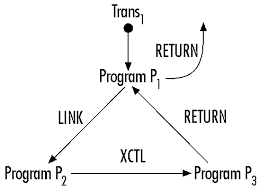
- In CICS, one program can call another program using three methods which are CALL(COBOL CALL), LINK(CICS), XCTL(CICS). There are various reasons why LINK, XCTL is preferred in CICS compared to CALL. One such reason is ‘A CALLed program remains in its last-used state after it returns control, so a second CALL finds the program in this state. LINK and XCTL commands, on the other hand, always find the “new” program in its initial state’. LINK always passes the control back to the calling module, whereas XCTL doesn’t return the control back to the calling module. CALL always passes the control back to the calling module.
- The basic difference between the CALL and LINK, XCTL is the syntax and how the data is passed between modules. Now if we look at the syntax of all three then it would look like
CALL USING [BY REFERENCE / BY CONTENT] identifier-1 identifier-2
EXEC CICS LINK PROGRAM(program-name) COMMAREA(commarea) LENGTH(length) END-EXEC
EXEC CICS XCTL PROGRAM(program-name) COMMAREA(commarea) LENGTH(length) END-EXEC
- The basic difference between the above three structure is, CALL can use any number of variables (of course within compiler limit) to pass from calling to called module. Again whenever we are doing a CALL BY REFERENCE only the reference or address of the memory location of the variable is passed to called module. But this not the case with LINK, XCTL. With LINK, XCTL there is no concept of CALL BY REFERENCE or CALL BY CONTENT. With LINK, XCTL we can pass only COMMAREA from one module to another. Called module can update the contents of COMMAREA. But COMMAREA has a limited size. But what should we do if we want to store large size arrays in COMMAREA. Again COMMAREA is common to all programs for a transaction. An array used by two modules might not be used by all modules under the transaction. So how to use the COMMAREA in an optimal manner.
- To resolve the above question we can use POINTER concept, the concept of CALL BY REFERENCE, the concept of passing REFERENCE of identifiers. Suppose we want to pass REFERENCE OF array WS-DATA-ARRAY from one module to another. Instead of putting entire WS-DATA-ARRAY in COMMAREA, we use the concept of CALL BY REFERENCE. Get the address of WS-DATA-ARRAY in a POINTER variable. Store this variable in COMMAREA. Pass the COMMAREA to called module through LINK or XCTL (In fact to any subsequent programs executed, as COMMAREA is visible to all modules under the transaction). Called module use the POINTER variable to locate the exact memory location and its data for further processing.
- So in this case, POINTER variable is used, because we don’t have any concept like CALL BY REFERENCE or CALL BY CONTENT in case of LINK, XCTL. The data present in COMMAREA can be passed to called module only. Again contents of COMMAREA are visible across multiple pseudo transactions. Hence to use COMMAREA in an optimal manner, as the size of COMMAREA is limited, POINTER is used to store the address of memory locations (need to be accessed in called module) in COMMAREA.
- But in batch in case of CALL BY REFERENCE we are already passing POINTER or REFERENCE or address of memory locations to be shared. This is taken cared for by the compiler itself. The REFERENCE is being passed through some SPECIAL REGISTER in case of CALL BY REFERENCE. This SPECIAL REGISTER solves the purpose of COMMAREA as explained above in this context. Hence in batch, we can safely go ahead without the usage of POINTER.
e.g.
Suppose in the main program P1VEDAT1 we have used the pointer STDRULE-PTR to call the program P1VEDSR2 then the syntax for this is as below
P1VEDAT1
01 WS-POINTERS.
05 STDRULE-PTR POINTER VALUE NULL.
Z1000-CALL-DB2-PBTE-RULE-PARA.
MOVE 'Z1000' TO WS01-PARA-NO
SET STDRULE-PTR TO ADDRESS OF ST-RECORD
CALL K-P1VEDSR2 USING STDRULE-PTR
FUNCTION-CODE
SET STDRULE-PTR TO ADDRESS OF ST-RECORD
IF ( PLAN-FATAL-ERR OF ST-RECORD )
SET WS-FATAL-ERR TO TRUE
PERFORM W1000-ERR-ST-RECORD
END-IF.
P1VEDSR2
LINKAGE SECTION.
01 LS-STDRULE-PTR POINTER.
PROCEDURE DIVISION USING LS-STDRULE-PTR
SET ADDRESS OF ST-RECORD TO LS-STDRULE-PTR
MOVE ZERO TO PLAN-SQLCODE
EVALUATE LS-FUNCTION-CODE
WHEN 'S'
WHEN 'I'
PERFORM S1000-SELECT-PARA
WHEN 'A'
PERFORM A1000-ADD-PARA
WHEN 'C'
PERFORM U1000-UPDATE-PARA
WHEN 'D'
PERFORM D1000-DELETE-PARA
WHEN OTHER
SET PLAN-FATAL-ERR TO TRUE
MOVE WS-PBTE-RULE-TABLE TO PLAN-DB2-TBL-NME
MOVE WS-P1VEDSR2 TO PLAN-PROGRAM
MOVE WS05-INVALID-FUNC-ERR TO WS05-ERR-MESSAGE
MOVE WS05-ERR-MESSAGE TO PLAN-ERR-MESSAGE
END-EVALUATE.
Read my other mainframe posts at Mainframe